Deepseek-OCR: संदर्भ ऑप्टिकल संपीड़न
DeepSeek OCR अगली पीढ़ी का ऑप्टिकल कैरेक्टर रिकॉग्निशन (OCR) समाधान है जिसे DeepSeek द्वारा बनाया गया है, जो अब उनके ओपन-सोर्स मॉडल हब और API के माध्यम से उपलब्ध है। यह जटिल दृश्य-पाठ इनपुट का समर्थन करता है—जिसमें स्कैन किए गए दस्तावेज़, फ़ोटो, फ़ॉर्म और मिश्रित-लेआउट पेज शामिल हैं—और पाठ निष्कर्षण, लेआउट समझ, और दृश्य-संदर्भ बोध को एक सहज मॉडल में एकीकृत करता है। DeepSeek OCR औद्योगिक पैमाने पर उच्च-रिज़ॉल्यूशन छवियों को परिवर्तित कर सकता है (उदाहरण के लिए, एक A100-क्लास GPU पर प्रतिदिन लाखों पृष्ठ)। नीचे DeepSeek OCR को मुफ्त में आज़माएं!
DeepSeek OCR लाइव डेमो आज़माएं
DeepSeek OCR की शक्ति को वास्तविक समय में अनुभव करें। अपनी छवियां अपलोड करें और उच्च सटीकता के साथ तत्काल पाठ निष्कर्षण देखें।
Loading DeepSeek OCR...
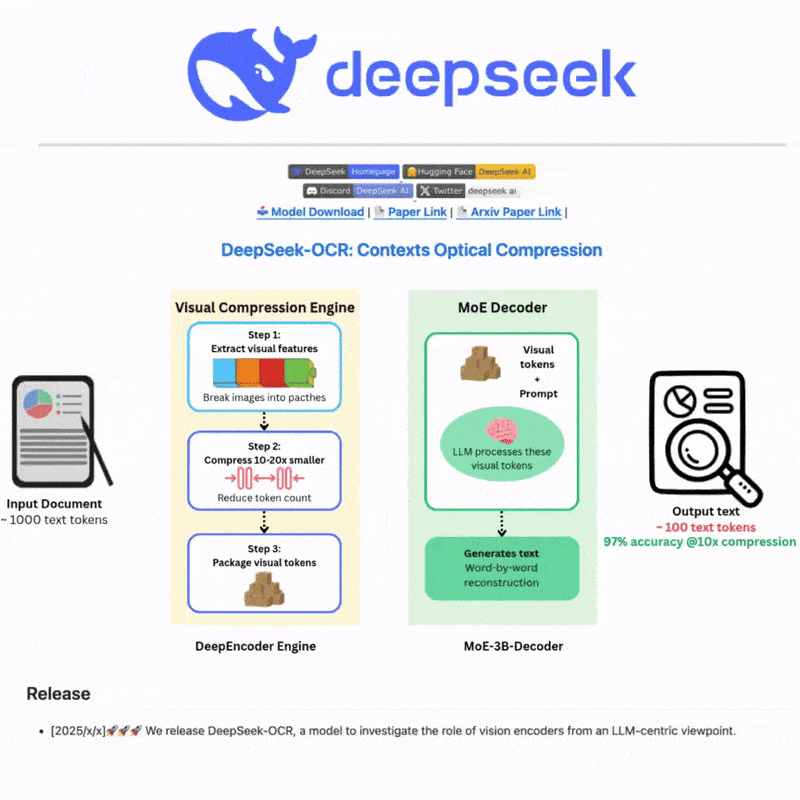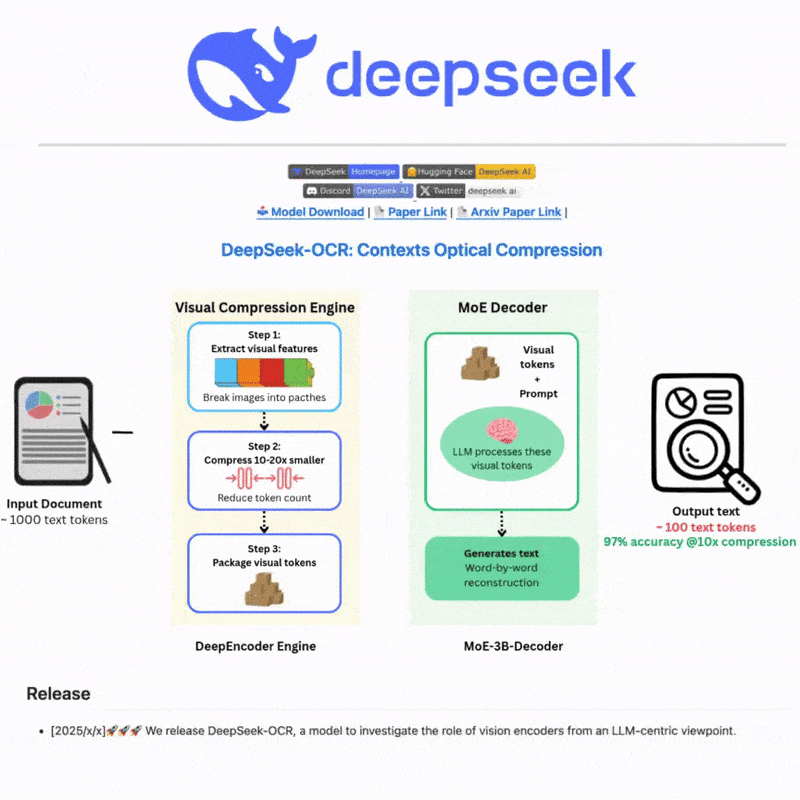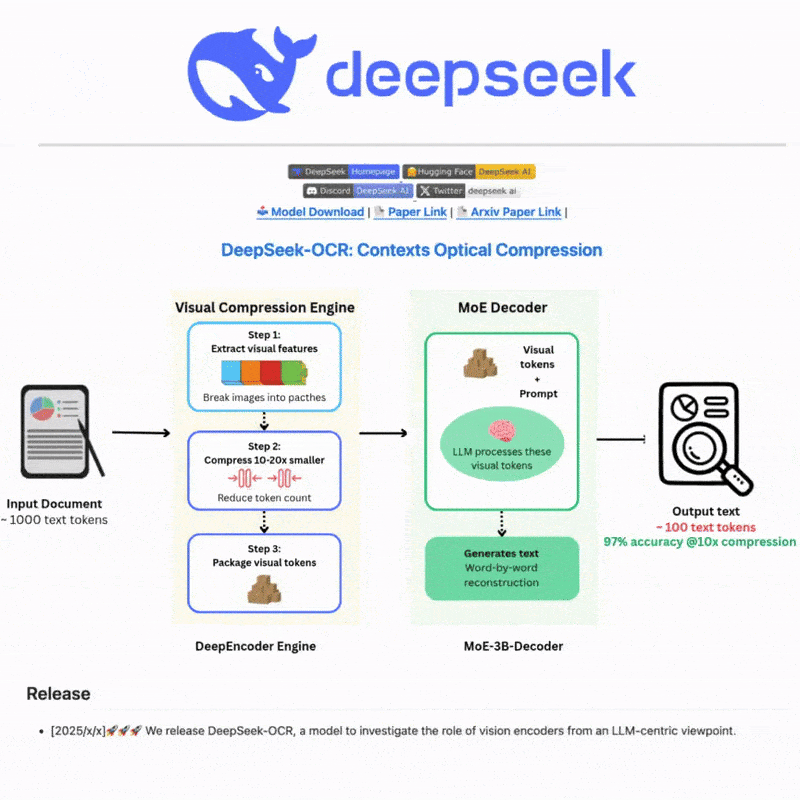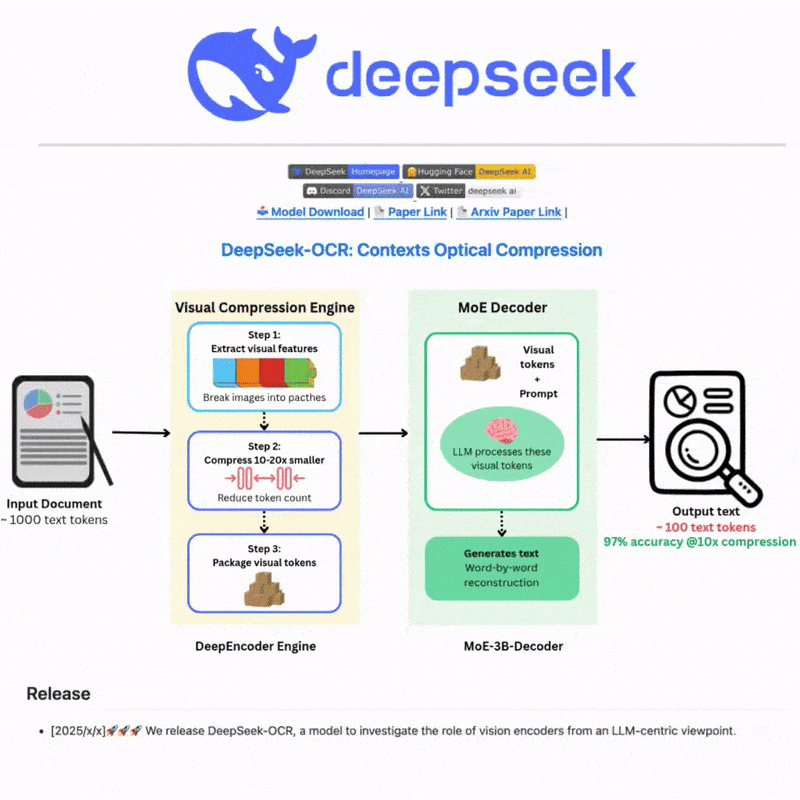
DeepSeek OCR क्या है
DeepSeek OCR एक उन्नत ऑप्टिकल कैरेक्टर रिकॉग्निशन प्रणाली है जो छवियों और दस्तावेज़ों से पाठ निकालने के लिए अत्याधुनिक AI तकनीक का लाभ उठाती है। परिष्कृत न्यूरल नेटवर्क और बहु-भाषा समर्थन के साथ निर्मित, यह जटिल परिदृश्यों के लिए शक्तिशाली पाठ पहचान और रिकॉग्निशन क्षमताएं प्रदान करती है, जो कुशल और लचीले पाठ प्रसंस्करण वर्कफ़्लो के लिए सहज वेब इंटरफ़ेस और मजबूत API एकीकरण दोनों प्रदान करती है।
- बहु-भाषा पाठ रिकॉग्निशनउन्नत न्यूरल नेटवर्क तकनीक और भाषा-जागरूक प्रसंस्करण क्षमताओं के साथ 80 से अधिक भाषाओं में छवियों से सटीक पाठ निकालें।
- जटिल दृश्य प्रबंधनपरिष्कृत पहचान एल्गोरिदम का उपयोग करके वक्र पाठ, एकाधिक दिशाओं और जटिल पृष्ठभूमि के साथ चुनौतीपूर्ण दस्तावेज़ लेआउट को प्रोसेस करें।
- उच्च सटीकता रिकॉग्निशनअनुकूलित ऑप्टिकल कैरेक्टर रिकॉग्निशन और उन्नत पोस्ट-प्रोसेसिंग तकनीकों के साथ उद्योग-अग्रणी पाठ निष्कर्षण सटीकता प्राप्त करें।
DeepSeek OCR की प्रमुख विशेषताएं
विश्वभर के पेशेवरों और डेवलपर्स के लिए डिज़ाइन की गई उन्नत AI-संचालित पाठ रिकॉग्निशन क्षमताएं।
बहु-भाषा समर्थन
भाषा-जागरूक कैरेक्टर रिकॉग्निशन के साथ चीनी, अंग्रेजी, अरबी और 80 से अधिक भाषाओं से पाठ पहचानें।
मजबूत पाठ पहचान
वक्र पाठ, एकाधिक दिशाओं और चुनौतीपूर्ण पृष्ठभूमि स्थितियों के साथ जटिल लेआउट में पाठ क्षेत्रों का पता लगाएं।
उच्च-गति प्रसंस्करण
वास्तविक समय पाठ निष्कर्षण परिणामों के लिए अनुकूलित इंफरेंस पाइपलाइन और GPU त्वरण के साथ छवियों को तेज़ी से प्रोसेस करें।
एकीकृत फ्रेमवर्क
एकीकृत पाठ पहचान और रिकॉग्निशन प्रणाली का उपयोग करें जो छवियों से एंड-टू-एंड पाठ निष्कर्षण प्रदान करती है।
संरचित लेआउट पुनर्प्राप्ति
उचित स्वरूपण के साथ पाठ निकालते समय पैराग्राफ, कॉलम और तालिकाओं सहित दस्तावेज़ संरचना को संरक्षित करें।
API एकीकरण
एकाधिक प्रोग्रामिंग भाषाओं के लिए RESTful API और SDK समर्थन के साथ अपने अनुप्रयोगों में शक्तिशाली OCR क्षमताओं को एकीकृत करें।
लोग X पर DeepSeek-OCR के बारे में क्या बात कर रहे हैं
यदि आप DeepSeek OCR का उपयोग करने का आनंद लेते हैं, तो कृपया हैशटैग के साथ Twitter पर अपना अनुभव साझा करें
Massively unexpected update from DeepSeek: a powerful, high-compression MoE OCR model.
— Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex) October 20, 2025
> In production, DeepSeek-OCR can generate 33 million pages of data per day for LLMs/VLMs using 20 nodes (x8 A100-40G).
They want ALL the tokens. You're welcome to have some too. https://t.co/ks97gjFuhd pic.twitter.com/mXV08ifRle
DeepSeek-OCR has some weird architectural choices for the LLM decoder: DeepSeek3B-MoE-A570M
— elie (@eliebakouch) October 20, 2025
-> uses MHA, no MLA (not even GQA?)
-> 2 shared experts (like DeepSeek V2, but V3 only has 1)
-> quite low sparsity, activation ratio is 12.5%. For V3 it’s 3.52%, for V2 it’s 5%
-> not… pic.twitter.com/nOYptOn3OE
Letsss gooo! DeepSeek just released a 3B OCR model on Hugging Face 🔥
— Vaibhav (VB) Srivastav (@reach_vb) October 20, 2025
Optimised to be token efficient AND scale ~200K+ pages/day on A100-40G
Same arch as DeepSeek VL2
Use it with Transformers, vLLM and more 🤗https://t.co/n4kHihS3At
NEW DeepSeek OCR model that outperforms dots ocr while prefilling 3x less tokens pic.twitter.com/g9T93PndFb
— Casper Hansen (@casper_hansen_) October 20, 2025
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
— vLLM (@vllm_project) October 20, 2025
🧠 Compresses visual contexts up to 20× while keeping… pic.twitter.com/bx3d7LnfaR
🚨 DeepSeek just did something wild.
— Alex Prompter (@alex_prompter) October 20, 2025
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That… pic.twitter.com/5ChoESanC8
is it just me or is this deepseek paper really…weird? like the flagship results are all about compression ratios and they’re gesturing at implications for LLM memory but… it’s an OCR model? are they suggesting that LLMs should ingest OCR embeddings of screenshots of old notes?? pic.twitter.com/ptxkgANIeW
— will brown (@willccbb) October 20, 2025
DeepSeek-OCR: https://t.co/Hww4tubUiS
— Ray Fernando (@RayFernando1337) October 20, 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
— Andrej Karpathy (@karpathy) October 20, 2025
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language… https://t.co/AxRXBdoO0F
Compress everything visually!
— 机器之心 JIQIZHIXIN (@jiqizhixin) October 20, 2025
DeepSeek has just released DeepSeek-OCR, a state-of-the-art OCR model with 3B parameters.
Core idea: explore long-context compression via 2D optical mapping.
Architecture:
- DeepEncoder → compresses high-res inputs into few vision tokens;
-… pic.twitter.com/qbRTi8ViLY