Deepseek-OCR: コンテキスト光学圧縮
DeepSeek OCRは、DeepSeekが構築した次世代の光学文字認識(OCR)ソリューションで、オープンソースモデルハブとAPIを通じて利用可能です。スキャンされた文書、写真、フォーム、混在レイアウトページなど、複雑な視覚テキスト入力に対応し、テキスト抽出、レイアウト理解、視覚コンテキスト理解を1つのシームレスなモデルに統合しています。DeepSeek OCRは、産業規模の高解像度画像処理が可能です(例:単一のA100クラスGPUで1日あたり数十万ページ)。以下で無料でDeepSeek OCRをお試しください!
DeepSeek OCRライブデモを試す
DeepSeek OCRのパワーをリアルタイムで体験してください。画像をアップロードして、高精度な即座のテキスト抽出をご覧いただけます。
Loading DeepSeek OCR...
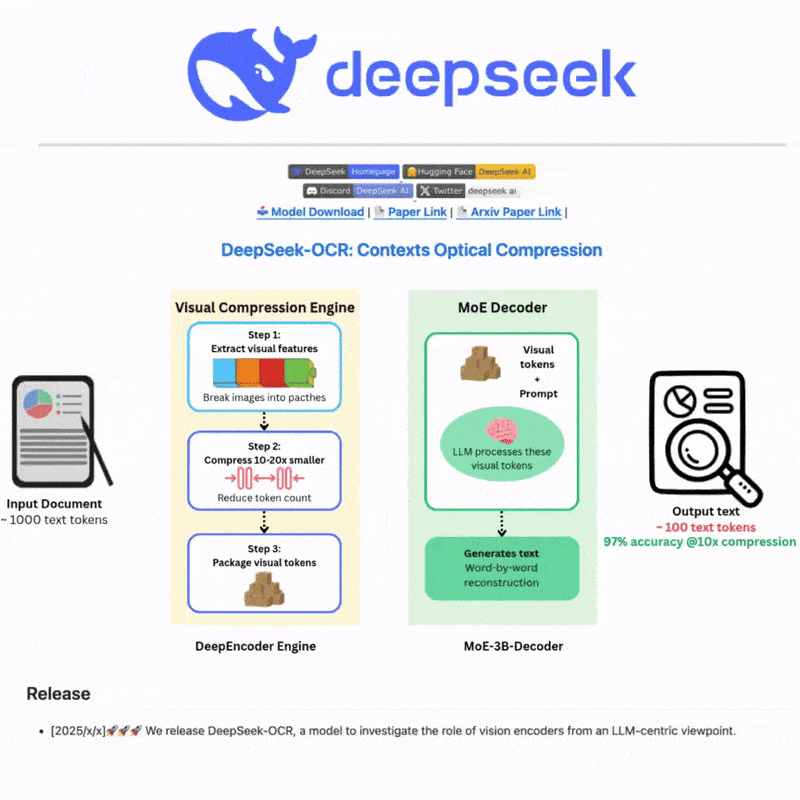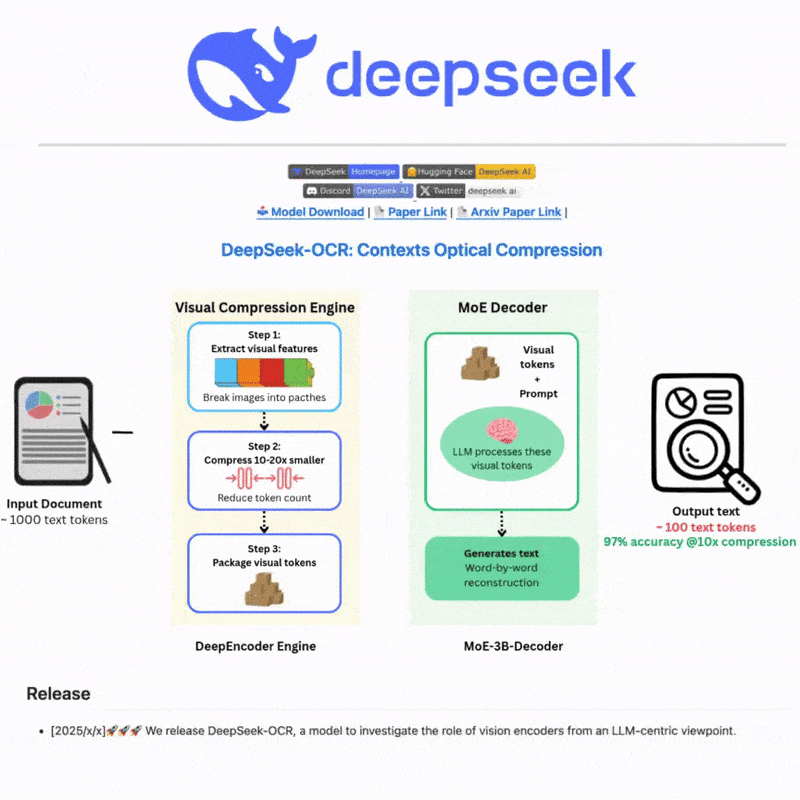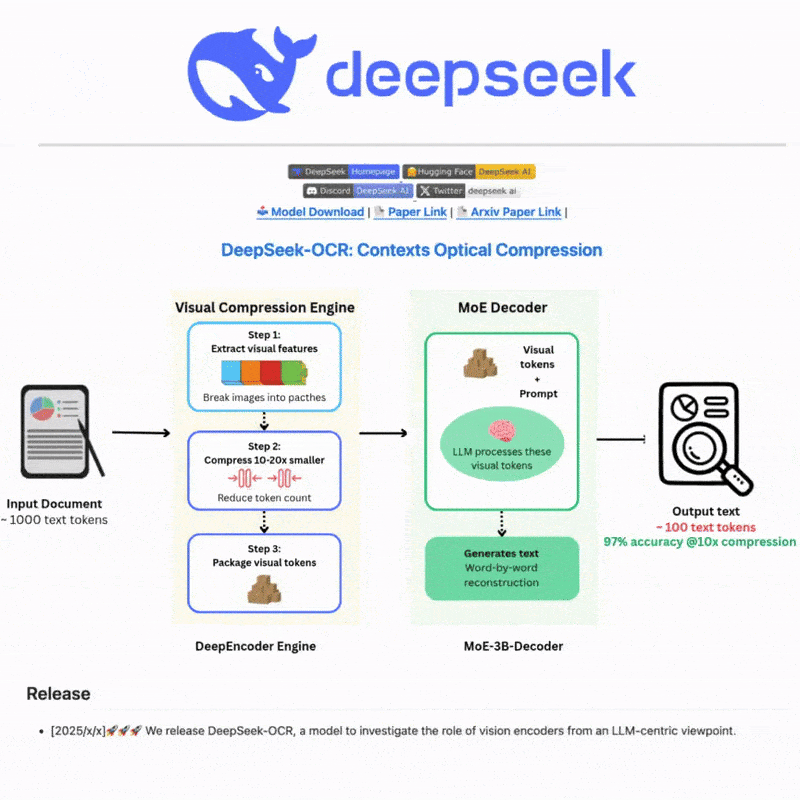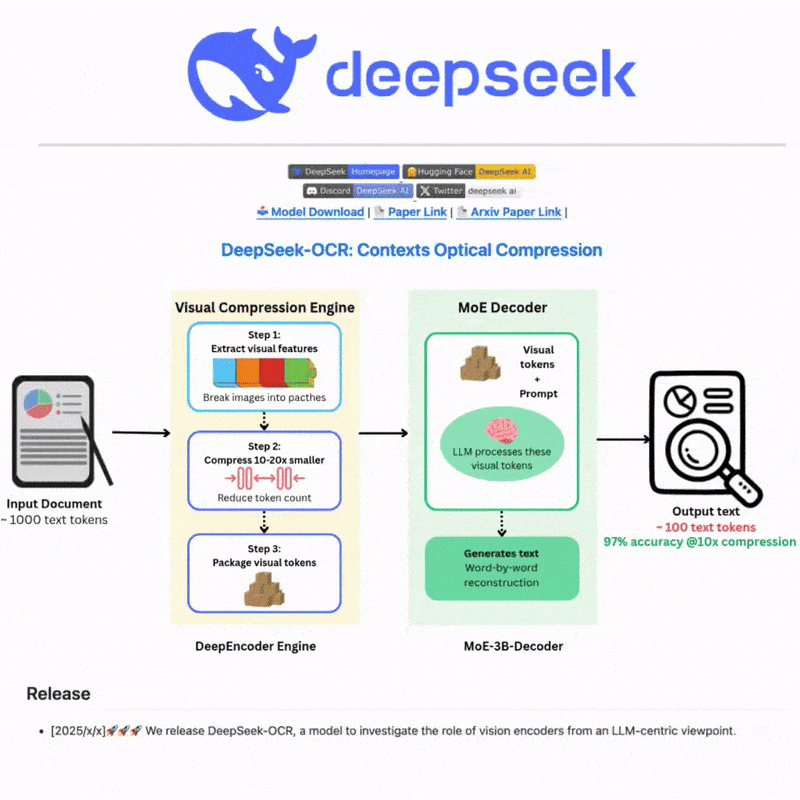
DeepSeek OCRとは
DeepSeek OCRは、最先端のAI技術を活用して画像や文書から正確にテキストを抽出する高度な光学文字認識システムです。洗練されたニューラルネットワークと多言語サポートで構築され、複雑なシナリオに対応する強力なテキスト検出と認識機能を提供します。直感的なWebインターフェースと堅牢なAPI統合により、効率的で柔軟なテキスト処理ワークフローを実現します。
- 多言語テキスト認識高度なニューラルネットワーク技術と言語認識処理機能により、80以上の言語の画像から正確にテキストを抽出します。
- 複雑なシーン処理高度な検出アルゴリズムを使用して、曲線テキスト、複数の方向、複雑な背景を含む困難な文書レイアウトを処理します。
- 高精度認識最適化された光学文字認識と高度な後処理技術により、業界トップレベルのテキスト抽出精度を実現します。
DeepSeek OCRの主な機能
世界中のプロフェッショナルと開発者向けに設計された高度なAI駆動テキスト認識機能。
多言語サポート
中国語、英語、アラビア語など80以上の言語のテキストを、言語認識文字認識で識別します。
堅牢なテキスト検出
曲線テキスト、複数の方向、困難な背景条件を含む複雑なレイアウトでテキスト領域を検出します。
高速処理
最適化された推論パイプラインとGPUアクセラレーションにより、リアルタイムのテキスト抽出結果を得るために画像を高速処理します。
統合フレームワーク
画像からのエンドツーエンドのテキスト抽出を提供する統合されたテキスト検出および認識システムを活用します。
構造化レイアウト復元
適切な書式でテキストを抽出しながら、段落、カラム、テーブルを含む文書構造を保持します。
API統合
RESTful APIと複数のプログラミング言語のSDKサポートにより、強力なOCR機能をアプリケーションに統合します。
XでのDeepSeek-OCRに関する話題
DeepSeek OCRをお楽しみいただけましたら、ハッシュタグを付けてTwitterで体験をシェアしてください
Massively unexpected update from DeepSeek: a powerful, high-compression MoE OCR model.
— Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex) October 20, 2025
> In production, DeepSeek-OCR can generate 33 million pages of data per day for LLMs/VLMs using 20 nodes (x8 A100-40G).
They want ALL the tokens. You're welcome to have some too. https://t.co/ks97gjFuhd pic.twitter.com/mXV08ifRle
DeepSeek-OCR has some weird architectural choices for the LLM decoder: DeepSeek3B-MoE-A570M
— elie (@eliebakouch) October 20, 2025
-> uses MHA, no MLA (not even GQA?)
-> 2 shared experts (like DeepSeek V2, but V3 only has 1)
-> quite low sparsity, activation ratio is 12.5%. For V3 it’s 3.52%, for V2 it’s 5%
-> not… pic.twitter.com/nOYptOn3OE
Letsss gooo! DeepSeek just released a 3B OCR model on Hugging Face 🔥
— Vaibhav (VB) Srivastav (@reach_vb) October 20, 2025
Optimised to be token efficient AND scale ~200K+ pages/day on A100-40G
Same arch as DeepSeek VL2
Use it with Transformers, vLLM and more 🤗https://t.co/n4kHihS3At
NEW DeepSeek OCR model that outperforms dots ocr while prefilling 3x less tokens pic.twitter.com/g9T93PndFb
— Casper Hansen (@casper_hansen_) October 20, 2025
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
— vLLM (@vllm_project) October 20, 2025
🧠 Compresses visual contexts up to 20× while keeping… pic.twitter.com/bx3d7LnfaR
🚨 DeepSeek just did something wild.
— Alex Prompter (@alex_prompter) October 20, 2025
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That… pic.twitter.com/5ChoESanC8
is it just me or is this deepseek paper really…weird? like the flagship results are all about compression ratios and they’re gesturing at implications for LLM memory but… it’s an OCR model? are they suggesting that LLMs should ingest OCR embeddings of screenshots of old notes?? pic.twitter.com/ptxkgANIeW
— will brown (@willccbb) October 20, 2025
DeepSeek-OCR: https://t.co/Hww4tubUiS
— Ray Fernando (@RayFernando1337) October 20, 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
— Andrej Karpathy (@karpathy) October 20, 2025
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language… https://t.co/AxRXBdoO0F
Compress everything visually!
— 机器之心 JIQIZHIXIN (@jiqizhixin) October 20, 2025
DeepSeek has just released DeepSeek-OCR, a state-of-the-art OCR model with 3B parameters.
Core idea: explore long-context compression via 2D optical mapping.
Architecture:
- DeepEncoder → compresses high-res inputs into few vision tokens;
-… pic.twitter.com/qbRTi8ViLY