Deepseek-OCR: 문맥 기반 광학 압축
DeepSeek OCR은 DeepSeek이 구축한 차세대 광학 문자 인식(OCR) 솔루션으로, 현재 오픈소스 모델 허브와 API를 통해 제공됩니다. 스캔된 문서, 사진, 양식 및 혼합 레이아웃 페이지를 포함한 복잡한 시각-텍스트 입력을 지원하며, 텍스트 추출, 레이아웃 이해 및 시각적 문맥 이해를 하나의 원활한 모델로 통합합니다. DeepSeek OCR은 단일 A100급 GPU에서 하루에 수십만 페이지 등 산업 규모의 고해상도 이미지를 변환할 수 있습니다. 아래에서 DeepSeek OCR을 무료로 사용해 보세요!
DeepSeek OCR 라이브 데모 체험
DeepSeek OCR의 강력한 기능을 실시간으로 경험해 보세요. 이미지를 업로드하면 높은 정확도로 즉시 텍스트를 추출합니다.
Loading DeepSeek OCR...
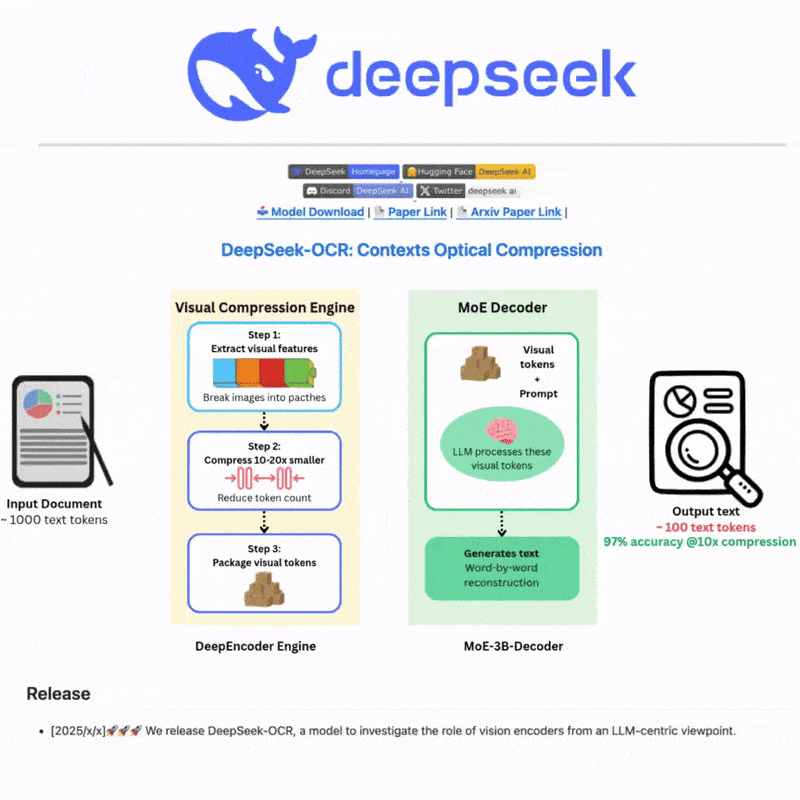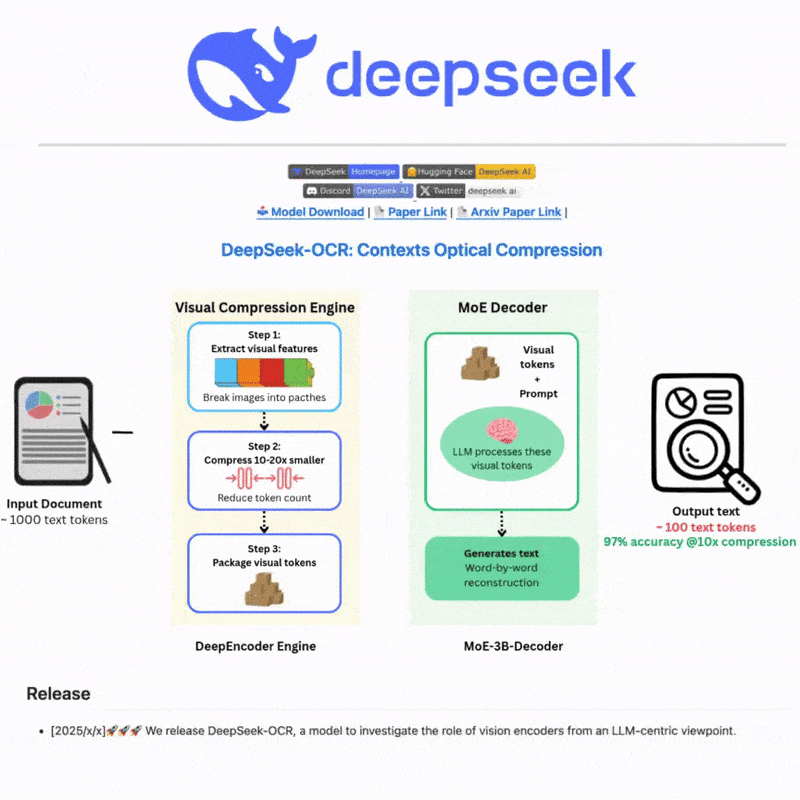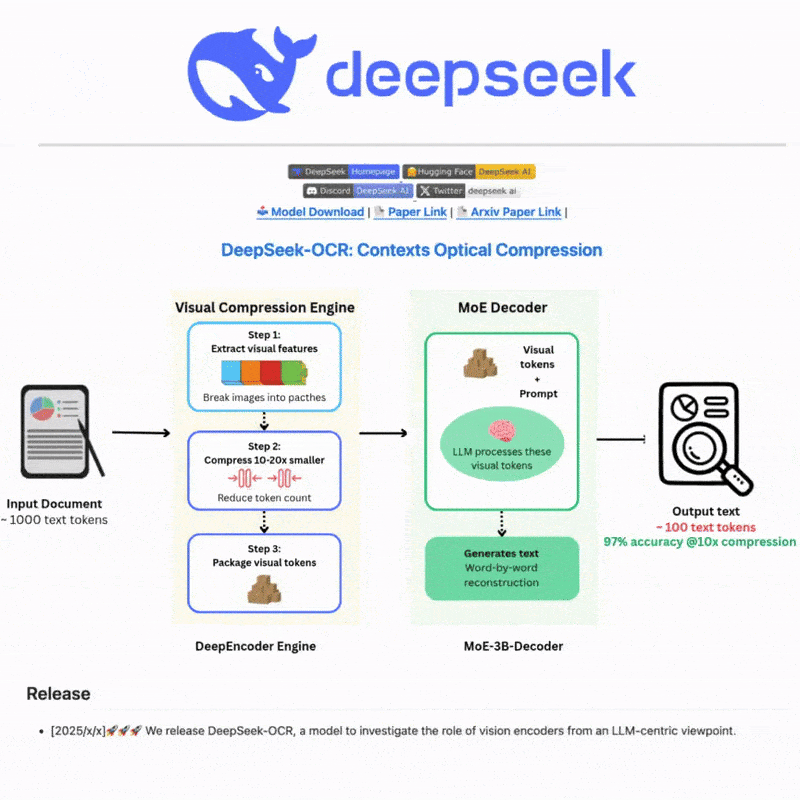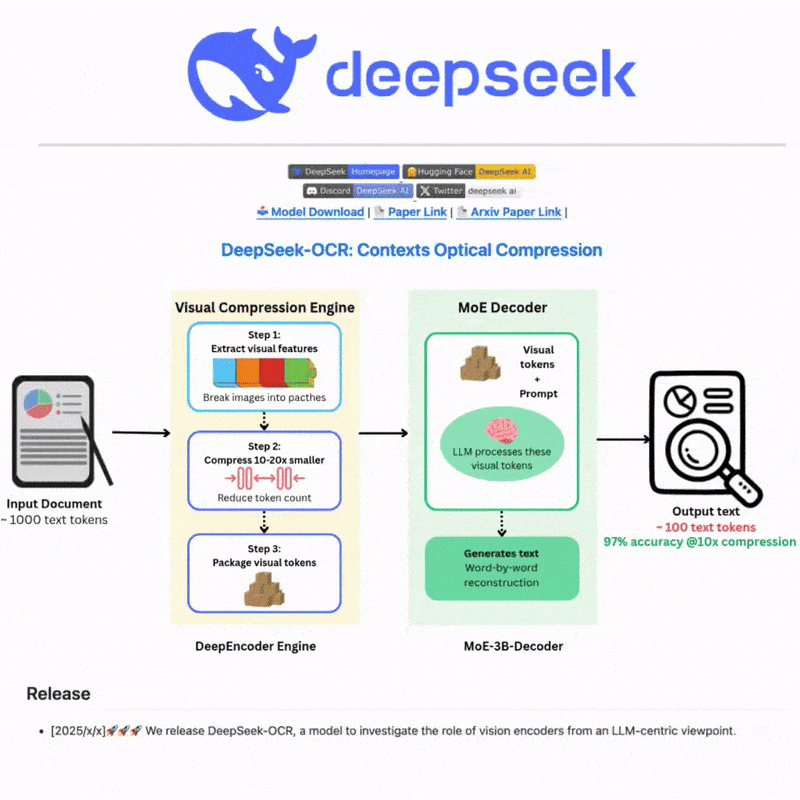
DeepSeek OCR이란 무엇인가요
DeepSeek OCR은 최첨단 AI 기술을 활용하여 이미지와 문서에서 텍스트를 정확하게 추출하는 고급 광학 문자 인식 시스템입니다. 정교한 신경망과 다국어 지원으로 구축되어 복잡한 시나리오에 대한 강력한 텍스트 감지 및 인식 기능을 제공하며, 직관적인 웹 인터페이스와 강력한 API 통합을 통해 효율적이고 유연한 텍스트 처리 워크플로를 제공합니다.
- 다국어 텍스트 인식고급 신경망 기술과 언어 인식 처리 기능을 통해 80개 이상의 언어로 된 이미지에서 텍스트를 정확하게 추출합니다.
- 복잡한 장면 처리정교한 감지 알고리즘을 사용하여 곡선 텍스트, 다양한 방향 및 복잡한 배경이 있는 까다로운 문서 레이아웃을 처리합니다.
- 높은 정확도의 인식최적화된 광학 문자 인식과 고급 후처리 기술을 통해 업계 최고 수준의 텍스트 추출 정확도를 달성합니다.
DeepSeek OCR의 주요 기능
전 세계 전문가와 개발자를 위해 설계된 고급 AI 기반 텍스트 인식 기능입니다.
다국어 지원
언어 인식 문자 인식을 통해 중국어, 영어, 아랍어 등 80개 이상의 언어로 된 텍스트를 인식합니다.
강력한 텍스트 감지
곡선 텍스트, 다양한 방향 및 까다로운 배경 조건이 있는 복잡한 레이아웃에서 텍스트 영역을 감지합니다.
고속 처리
최적화된 추론 파이프라인과 GPU 가속을 통해 이미지를 빠르게 처리하여 실시간 텍스트 추출 결과를 제공합니다.
통합 프레임워크
이미지에서 엔드투엔드 텍스트 추출을 제공하는 통합된 텍스트 감지 및 인식 시스템을 활용합니다.
구조화된 레이아웃 복원
적절한 형식으로 텍스트를 추출하는 동안 단락, 열 및 표를 포함한 문서 구조를 보존합니다.
API 통합
RESTful API와 여러 프로그래밍 언어용 SDK 지원을 통해 강력한 OCR 기능을 애플리케이션에 통합합니다.
사람들이 X에서 DeepSeek-OCR에 대해 이야기하는 내용
DeepSeek OCR을 즐겁게 사용하고 계시다면, 해시태그와 함께 Twitter에서 경험을 공유해 주세요
Massively unexpected update from DeepSeek: a powerful, high-compression MoE OCR model.
— Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex) October 20, 2025
> In production, DeepSeek-OCR can generate 33 million pages of data per day for LLMs/VLMs using 20 nodes (x8 A100-40G).
They want ALL the tokens. You're welcome to have some too. https://t.co/ks97gjFuhd pic.twitter.com/mXV08ifRle
DeepSeek-OCR has some weird architectural choices for the LLM decoder: DeepSeek3B-MoE-A570M
— elie (@eliebakouch) October 20, 2025
-> uses MHA, no MLA (not even GQA?)
-> 2 shared experts (like DeepSeek V2, but V3 only has 1)
-> quite low sparsity, activation ratio is 12.5%. For V3 it’s 3.52%, for V2 it’s 5%
-> not… pic.twitter.com/nOYptOn3OE
Letsss gooo! DeepSeek just released a 3B OCR model on Hugging Face 🔥
— Vaibhav (VB) Srivastav (@reach_vb) October 20, 2025
Optimised to be token efficient AND scale ~200K+ pages/day on A100-40G
Same arch as DeepSeek VL2
Use it with Transformers, vLLM and more 🤗https://t.co/n4kHihS3At
NEW DeepSeek OCR model that outperforms dots ocr while prefilling 3x less tokens pic.twitter.com/g9T93PndFb
— Casper Hansen (@casper_hansen_) October 20, 2025
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
— vLLM (@vllm_project) October 20, 2025
🧠 Compresses visual contexts up to 20× while keeping… pic.twitter.com/bx3d7LnfaR
🚨 DeepSeek just did something wild.
— Alex Prompter (@alex_prompter) October 20, 2025
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That… pic.twitter.com/5ChoESanC8
is it just me or is this deepseek paper really…weird? like the flagship results are all about compression ratios and they’re gesturing at implications for LLM memory but… it’s an OCR model? are they suggesting that LLMs should ingest OCR embeddings of screenshots of old notes?? pic.twitter.com/ptxkgANIeW
— will brown (@willccbb) October 20, 2025
DeepSeek-OCR: https://t.co/Hww4tubUiS
— Ray Fernando (@RayFernando1337) October 20, 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
— Andrej Karpathy (@karpathy) October 20, 2025
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language… https://t.co/AxRXBdoO0F
Compress everything visually!
— 机器之心 JIQIZHIXIN (@jiqizhixin) October 20, 2025
DeepSeek has just released DeepSeek-OCR, a state-of-the-art OCR model with 3B parameters.
Core idea: explore long-context compression via 2D optical mapping.
Architecture:
- DeepEncoder → compresses high-res inputs into few vision tokens;
-… pic.twitter.com/qbRTi8ViLY