Deepseek-OCR: Pemampatan Optik Konteks
DeepSeek OCR adalah penyelesaian pengenalan aksara optik (OCR) generasi baharu yang dibina oleh DeepSeek, kini tersedia melalui pusat model sumber terbuka dan API mereka. Ia menyokong input visual-teks yang kompleks—termasuk dokumen imbasan, foto, borang dan halaman susun atur campuran—dan menyatukan pengekstrakan teks, pemahaman susun atur, dan pemahaman konteks visual menjadi satu model yang lancar. DeepSeek OCR boleh menukar imej resolusi tinggi pada skala perindustrian (cth., ratusan ribu halaman setiap hari pada satu GPU kelas A100). Cuba DeepSeek OCR secara percuma di bawah!
Cuba Demo Langsung DeepSeek OCR
Rasai kuasa DeepSeek OCR secara masa nyata. Muat naik imej anda dan lihat pengekstrakan teks segera dengan ketepatan tinggi.
Loading DeepSeek OCR...
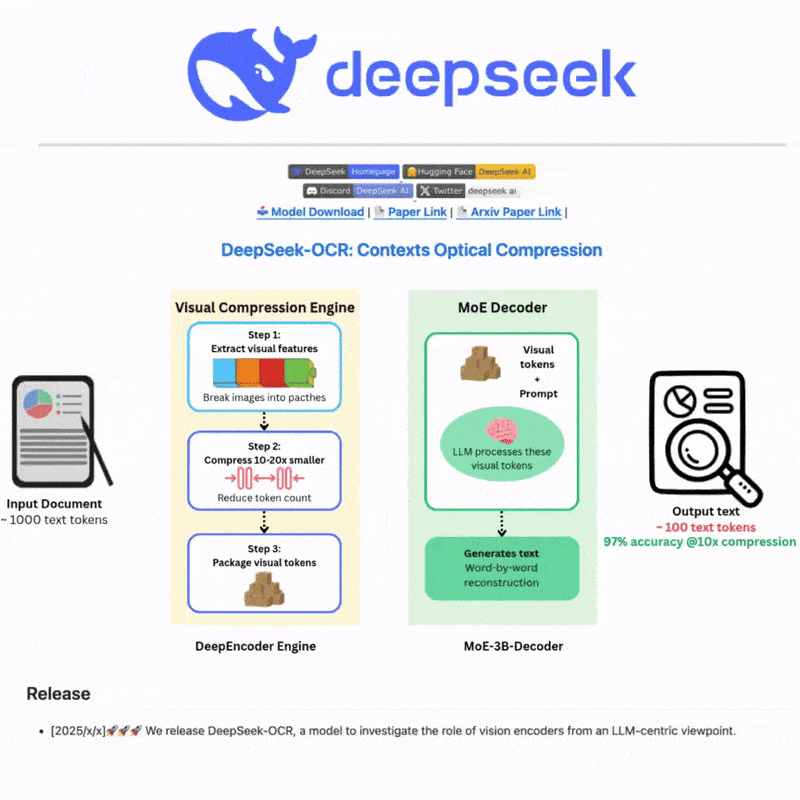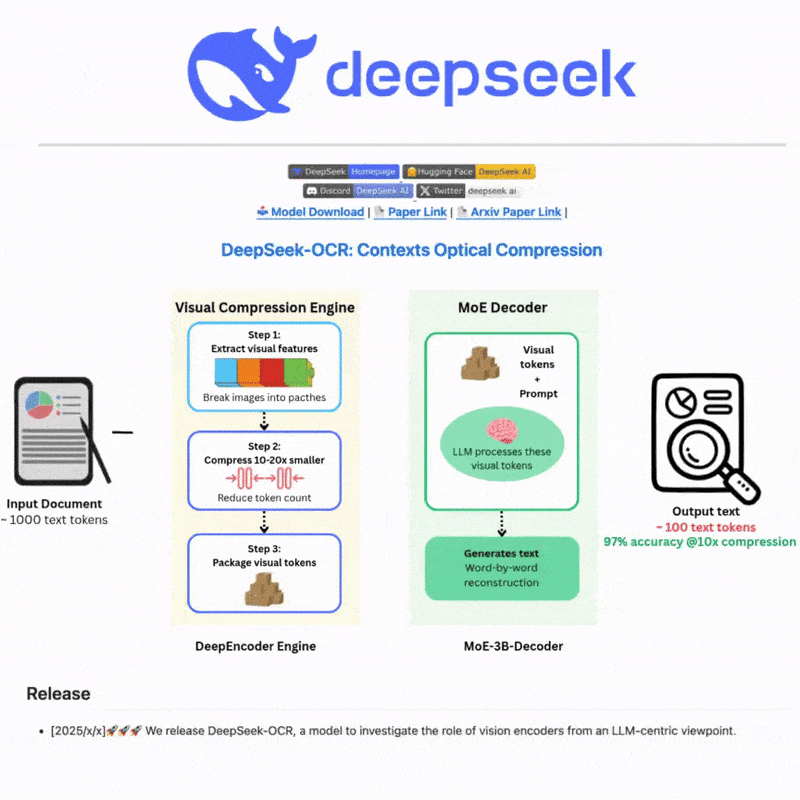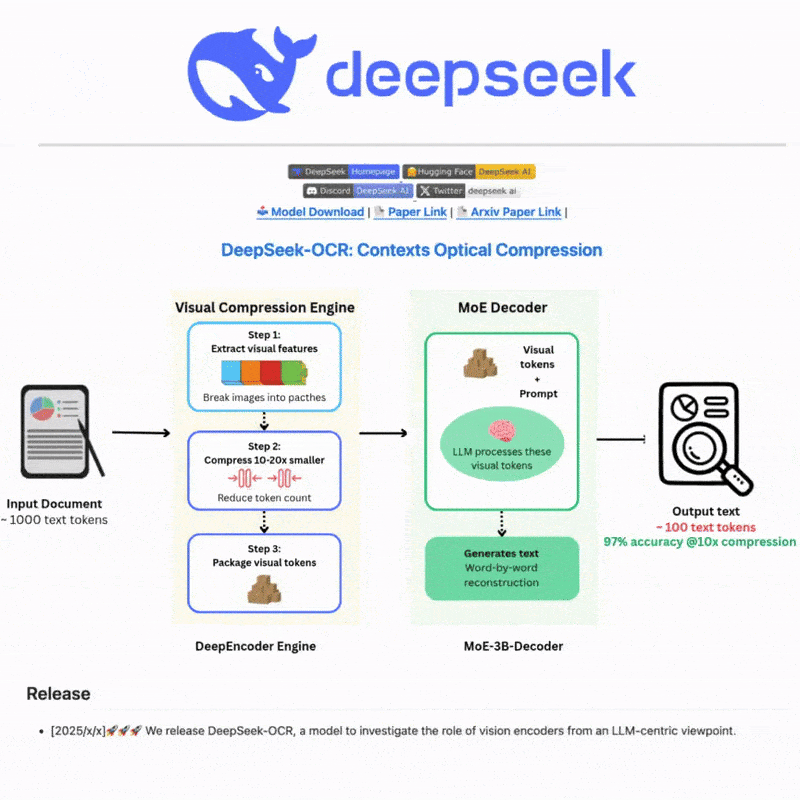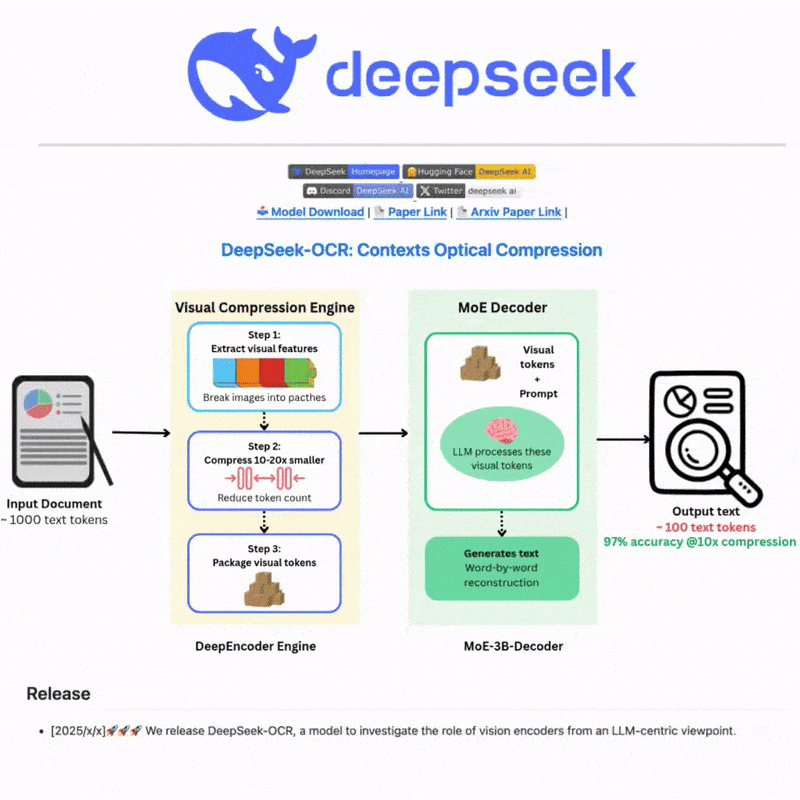
Apakah DeepSeek OCR
DeepSeek OCR adalah sistem pengenalan aksara optik canggih yang menggunakan teknologi AI termaju untuk mengekstrak teks daripada imej dan dokumen dengan tepat. Dibina dengan rangkaian neural yang canggih dan sokongan pelbagai bahasa, ia menyediakan keupayaan pengesanan dan pengenalan teks yang berkuasa untuk senario yang kompleks, menawarkan antara muka web yang intuitif dan integrasi API yang mantap untuk aliran kerja pemprosesan teks yang cekap dan fleksibel.
- Pengenalan Teks Pelbagai BahasaEkstrak teks dengan tepat daripada imej dalam lebih 80 bahasa dengan teknologi rangkaian neural termaju dan keupayaan pemprosesan yang sedar bahasa.
- Pengendalian Pemandangan KompleksProses susun atur dokumen yang mencabar dengan teks melengkung, pelbagai orientasi, dan latar belakang yang kompleks menggunakan algoritma pengesanan yang canggih.
- Pengenalan Ketepatan TinggiCapai ketepatan pengekstrakan teks terkemuka industri dengan pengenalan aksara optik yang dioptimumkan dan teknik pasca-pemprosesan yang canggih.
Ciri-ciri Utama DeepSeek OCR
Keupayaan pengenalan teks berkuasa AI canggih yang direka untuk profesional dan pembangun di seluruh dunia.
Sokongan Pelbagai Bahasa
Kenali teks daripada lebih 80 bahasa termasuk Cina, Inggeris, Arab, dan banyak lagi dengan pengenalan aksara yang sedar bahasa.
Pengesanan Teks Mantap
Kesan kawasan teks dalam susun atur kompleks dengan teks melengkung, pelbagai orientasi, dan keadaan latar belakang yang mencabar.
Pemprosesan Berkelajuan Tinggi
Proses imej dengan pantas dengan saluran inferens yang dioptimumkan dan percepatan GPU untuk hasil pengekstrakan teks masa nyata.
Rangka Kerja Bersatu
Gunakan sistem pengesanan dan pengenalan teks bersepadu yang menyediakan pengekstrakan teks hujung ke hujung daripada imej.
Pemulihan Susun Atur Berstruktur
Pelihara struktur dokumen termasuk perenggan, lajur, dan jadual semasa mengekstrak teks dengan pemformatan yang betul.
Integrasi API
Integrasikan keupayaan OCR yang berkuasa ke dalam aplikasi anda dengan API REST dan sokongan SDK untuk pelbagai bahasa pengaturcaraan.
Apa Yang Orang Perkatakan Tentang DeepSeek-OCR di X
Jika anda menikmati penggunaan DeepSeek OCR, sila kongsi pengalaman anda di Twitter dengan hashtag
Massively unexpected update from DeepSeek: a powerful, high-compression MoE OCR model.
— Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex) October 20, 2025
> In production, DeepSeek-OCR can generate 33 million pages of data per day for LLMs/VLMs using 20 nodes (x8 A100-40G).
They want ALL the tokens. You're welcome to have some too. https://t.co/ks97gjFuhd pic.twitter.com/mXV08ifRle
DeepSeek-OCR has some weird architectural choices for the LLM decoder: DeepSeek3B-MoE-A570M
— elie (@eliebakouch) October 20, 2025
-> uses MHA, no MLA (not even GQA?)
-> 2 shared experts (like DeepSeek V2, but V3 only has 1)
-> quite low sparsity, activation ratio is 12.5%. For V3 it’s 3.52%, for V2 it’s 5%
-> not… pic.twitter.com/nOYptOn3OE
Letsss gooo! DeepSeek just released a 3B OCR model on Hugging Face 🔥
— Vaibhav (VB) Srivastav (@reach_vb) October 20, 2025
Optimised to be token efficient AND scale ~200K+ pages/day on A100-40G
Same arch as DeepSeek VL2
Use it with Transformers, vLLM and more 🤗https://t.co/n4kHihS3At
NEW DeepSeek OCR model that outperforms dots ocr while prefilling 3x less tokens pic.twitter.com/g9T93PndFb
— Casper Hansen (@casper_hansen_) October 20, 2025
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
— vLLM (@vllm_project) October 20, 2025
🧠 Compresses visual contexts up to 20× while keeping… pic.twitter.com/bx3d7LnfaR
🚨 DeepSeek just did something wild.
— Alex Prompter (@alex_prompter) October 20, 2025
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That… pic.twitter.com/5ChoESanC8
is it just me or is this deepseek paper really…weird? like the flagship results are all about compression ratios and they’re gesturing at implications for LLM memory but… it’s an OCR model? are they suggesting that LLMs should ingest OCR embeddings of screenshots of old notes?? pic.twitter.com/ptxkgANIeW
— will brown (@willccbb) October 20, 2025
DeepSeek-OCR: https://t.co/Hww4tubUiS
— Ray Fernando (@RayFernando1337) October 20, 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
— Andrej Karpathy (@karpathy) October 20, 2025
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language… https://t.co/AxRXBdoO0F
Compress everything visually!
— 机器之心 JIQIZHIXIN (@jiqizhixin) October 20, 2025
DeepSeek has just released DeepSeek-OCR, a state-of-the-art OCR model with 3B parameters.
Core idea: explore long-context compression via 2D optical mapping.
Architecture:
- DeepEncoder → compresses high-res inputs into few vision tokens;
-… pic.twitter.com/qbRTi8ViLY