Deepseek-OCR: Nén quang học theo ngữ cảnh
DeepSeek OCR là giải pháp nhận dạng ký tự quang học (OCR) thế hệ mới được xây dựng bởi DeepSeek, hiện có sẵn thông qua mô hình mã nguồn mở và API của họ. Nó hỗ trợ các đầu vào văn bản-hình ảnh phức tạp—bao gồm tài liệu quét, ảnh chụp, biểu mẫu và các trang bố cục hỗn hợp—và thống nhất việc trích xuất văn bản, hiểu bố cục và hiểu ngữ cảnh hình ảnh vào một mô hình liền mạch. DeepSeek OCR có thể chuyển đổi hình ảnh độ phân giải cao ở quy mô công nghiệp (ví dụ: hàng trăm nghìn trang mỗi ngày trên một GPU cấp A100). Hãy dùng thử DeepSeek OCR miễn phí ngay bên dưới!
Dùng thử bản demo trực tiếp DeepSeek OCR
Trải nghiệm sức mạnh của DeepSeek OCR theo thời gian thực. Tải lên hình ảnh của bạn và xem kết quả trích xuất văn bản tức thì với độ chính xác cao.
Loading DeepSeek OCR...
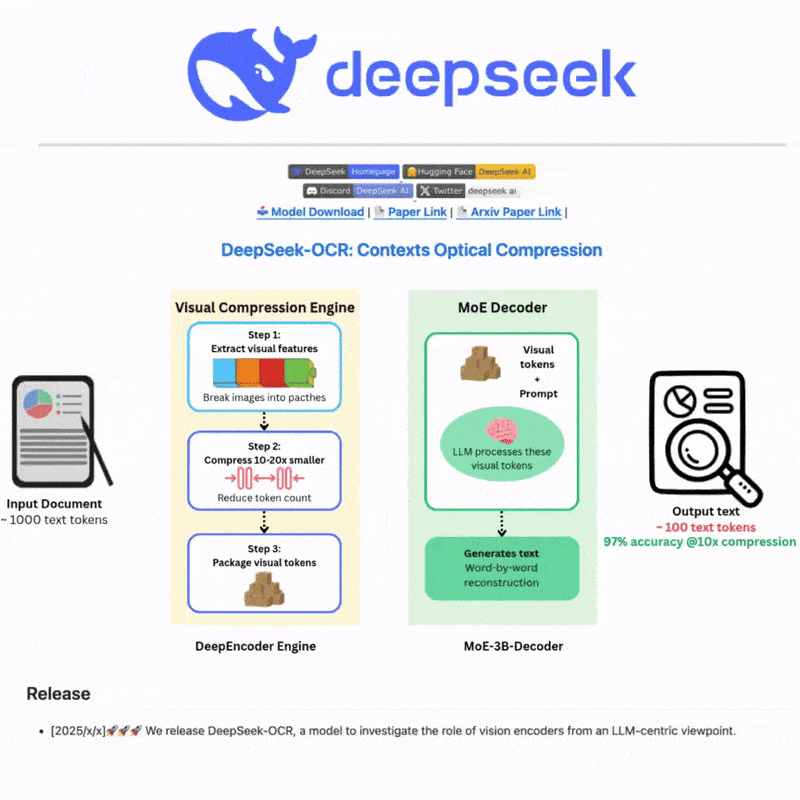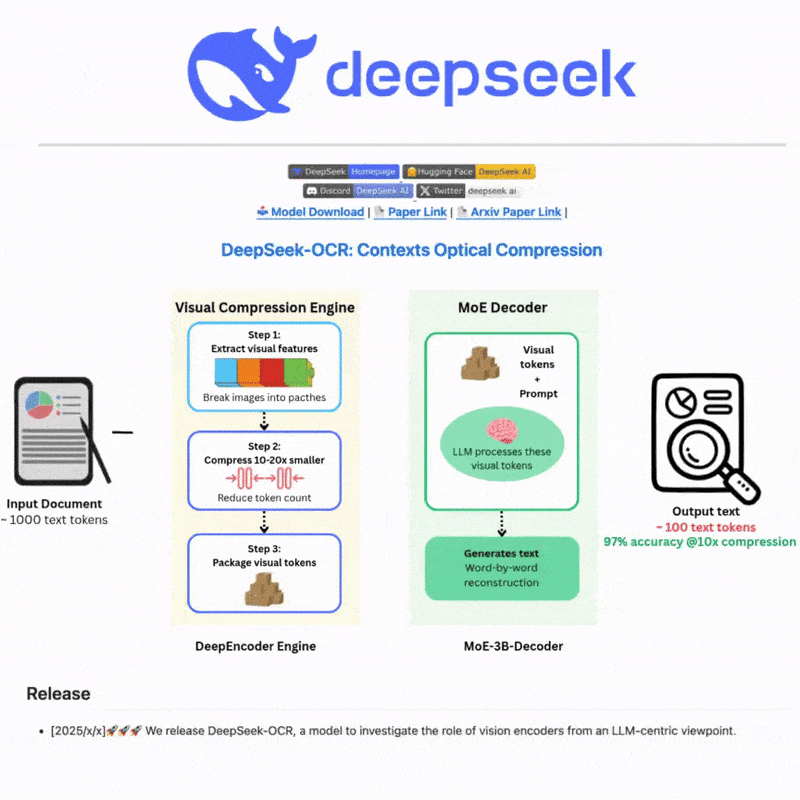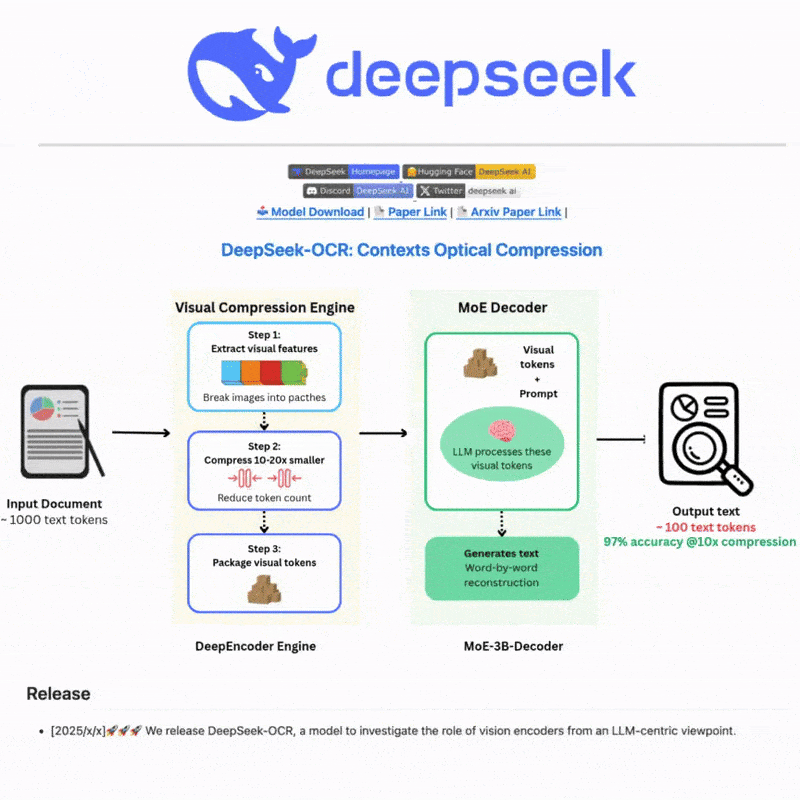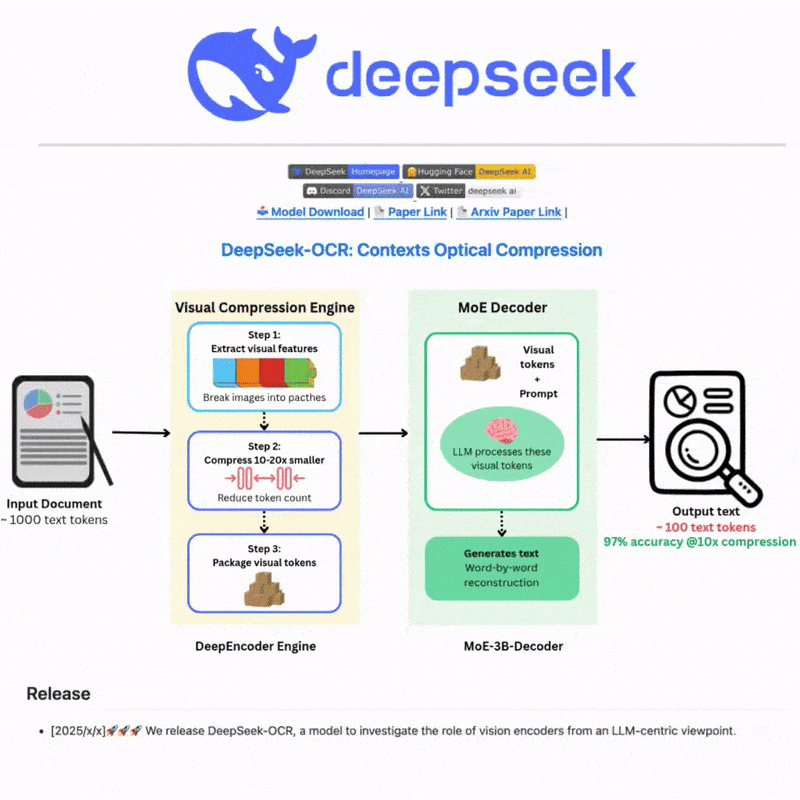
DeepSeek OCR là gì
DeepSeek OCR là một hệ thống nhận dạng ký tự quang học tiên tiến tận dụng công nghệ AI tiên tiến để trích xuất văn bản chính xác từ hình ảnh và tài liệu. Được xây dựng với các mạng nơ-ron phức tạp và hỗ trợ đa ngôn ngữ, nó cung cấp khả năng phát hiện và nhận dạng văn bản mạnh mẽ cho các tình huống phức tạp, cung cấp cả giao diện web trực quan và tích hợp API mạnh mẽ cho quy trình xử lý văn bản hiệu quả và linh hoạt.
- Nhận dạng văn bản đa ngôn ngữTrích xuất chính xác văn bản từ hình ảnh bằng hơn 80 ngôn ngữ với công nghệ mạng nơ-ron tiên tiến và khả năng xử lý nhận biết ngôn ngữ.
- Xử lý cảnh phức tạpXử lý các bố cục tài liệu khó khăn với văn bản cong, nhiều hướng và nền phức tạp bằng các thuật toán phát hiện tinh vi.
- Nhận dạng độ chính xác caoĐạt được độ chính xác trích xuất văn bản hàng đầu trong ngành với nhận dạng ký tự quang học được tối ưu hóa và các kỹ thuật hậu xử lý tiên tiến.
Tính năng chính của DeepSeek OCR
Khả năng nhận dạng văn bản được hỗ trợ bởi AI tiên tiến được thiết kế cho các chuyên gia và nhà phát triển trên toàn thế giới.
Hỗ trợ đa ngôn ngữ
Nhận dạng văn bản từ hơn 80 ngôn ngữ bao gồm tiếng Trung, tiếng Anh, tiếng Ả Rập và nhiều hơn nữa với nhận dạng ký tự nhận biết ngôn ngữ.
Phát hiện văn bản mạnh mẽ
Phát hiện các vùng văn bản trong bố cục phức tạp với văn bản cong, nhiều hướng và điều kiện nền khó khăn.
Xử lý tốc độ cao
Xử lý hình ảnh nhanh chóng với pipeline suy luận được tối ưu hóa và tăng tốc GPU cho kết quả trích xuất văn bản theo thời gian thực.
Framework thống nhất
Sử dụng hệ thống phát hiện và nhận dạng văn bản tích hợp cung cấp trích xuất văn bản từ đầu đến cuối từ hình ảnh.
Khôi phục bố cục có cấu trúc
Bảo toàn cấu trúc tài liệu bao gồm đoạn văn, cột và bảng trong khi trích xuất văn bản với định dạng phù hợp.
Tích hợp API
Tích hợp khả năng OCR mạnh mẽ vào ứng dụng của bạn với API RESTful và hỗ trợ SDK cho nhiều ngôn ngữ lập trình.
Mọi người đang nói gì về DeepSeek-OCR trên X
Nếu bạn thích sử dụng DeepSeek OCR, vui lòng chia sẻ trải nghiệm của bạn trên Twitter với hashtag
Massively unexpected update from DeepSeek: a powerful, high-compression MoE OCR model.
— Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex) October 20, 2025
> In production, DeepSeek-OCR can generate 33 million pages of data per day for LLMs/VLMs using 20 nodes (x8 A100-40G).
They want ALL the tokens. You're welcome to have some too. https://t.co/ks97gjFuhd pic.twitter.com/mXV08ifRle
DeepSeek-OCR has some weird architectural choices for the LLM decoder: DeepSeek3B-MoE-A570M
— elie (@eliebakouch) October 20, 2025
-> uses MHA, no MLA (not even GQA?)
-> 2 shared experts (like DeepSeek V2, but V3 only has 1)
-> quite low sparsity, activation ratio is 12.5%. For V3 it’s 3.52%, for V2 it’s 5%
-> not… pic.twitter.com/nOYptOn3OE
Letsss gooo! DeepSeek just released a 3B OCR model on Hugging Face 🔥
— Vaibhav (VB) Srivastav (@reach_vb) October 20, 2025
Optimised to be token efficient AND scale ~200K+ pages/day on A100-40G
Same arch as DeepSeek VL2
Use it with Transformers, vLLM and more 🤗https://t.co/n4kHihS3At
NEW DeepSeek OCR model that outperforms dots ocr while prefilling 3x less tokens pic.twitter.com/g9T93PndFb
— Casper Hansen (@casper_hansen_) October 20, 2025
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
— vLLM (@vllm_project) October 20, 2025
🧠 Compresses visual contexts up to 20× while keeping… pic.twitter.com/bx3d7LnfaR
🚨 DeepSeek just did something wild.
— Alex Prompter (@alex_prompter) October 20, 2025
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That… pic.twitter.com/5ChoESanC8
is it just me or is this deepseek paper really…weird? like the flagship results are all about compression ratios and they’re gesturing at implications for LLM memory but… it’s an OCR model? are they suggesting that LLMs should ingest OCR embeddings of screenshots of old notes?? pic.twitter.com/ptxkgANIeW
— will brown (@willccbb) October 20, 2025
DeepSeek-OCR: https://t.co/Hww4tubUiS
— Ray Fernando (@RayFernando1337) October 20, 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
— Andrej Karpathy (@karpathy) October 20, 2025
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language… https://t.co/AxRXBdoO0F
Compress everything visually!
— 机器之心 JIQIZHIXIN (@jiqizhixin) October 20, 2025
DeepSeek has just released DeepSeek-OCR, a state-of-the-art OCR model with 3B parameters.
Core idea: explore long-context compression via 2D optical mapping.
Architecture:
- DeepEncoder → compresses high-res inputs into few vision tokens;
-… pic.twitter.com/qbRTi8ViLY