试用 DeepSeek OCR 在线演示
实时体验 DeepSeek OCR 的强大功能。上传您的图像,即可看到高准确度的即时文本提取。
Loading DeepSeek OCR...
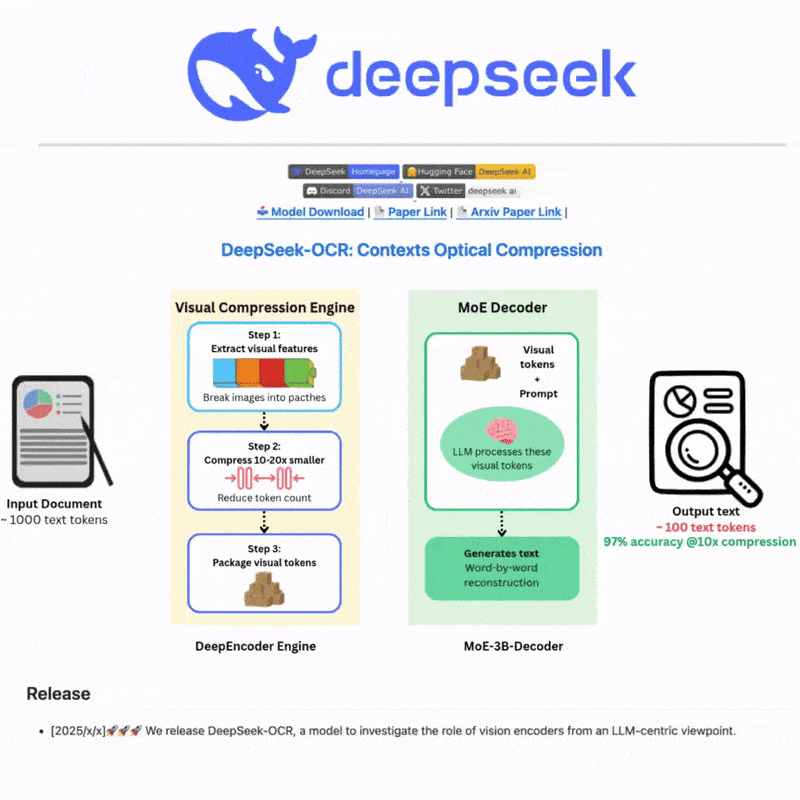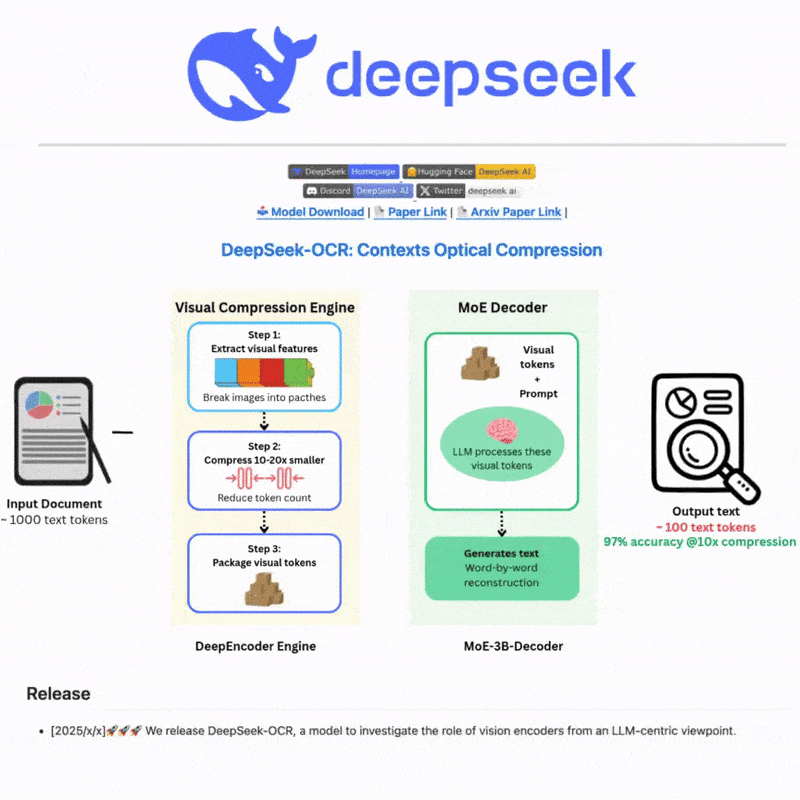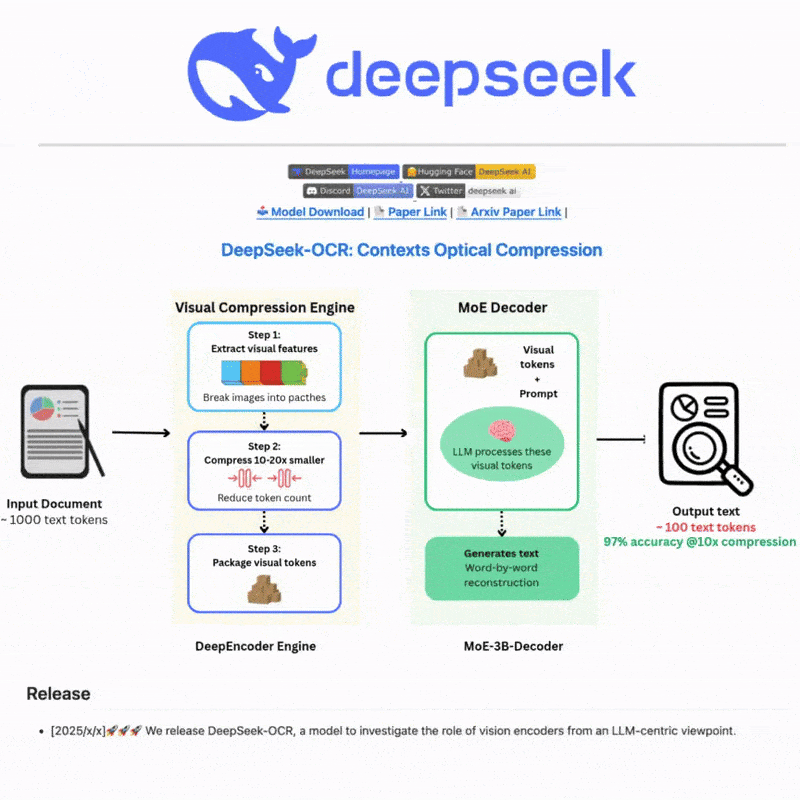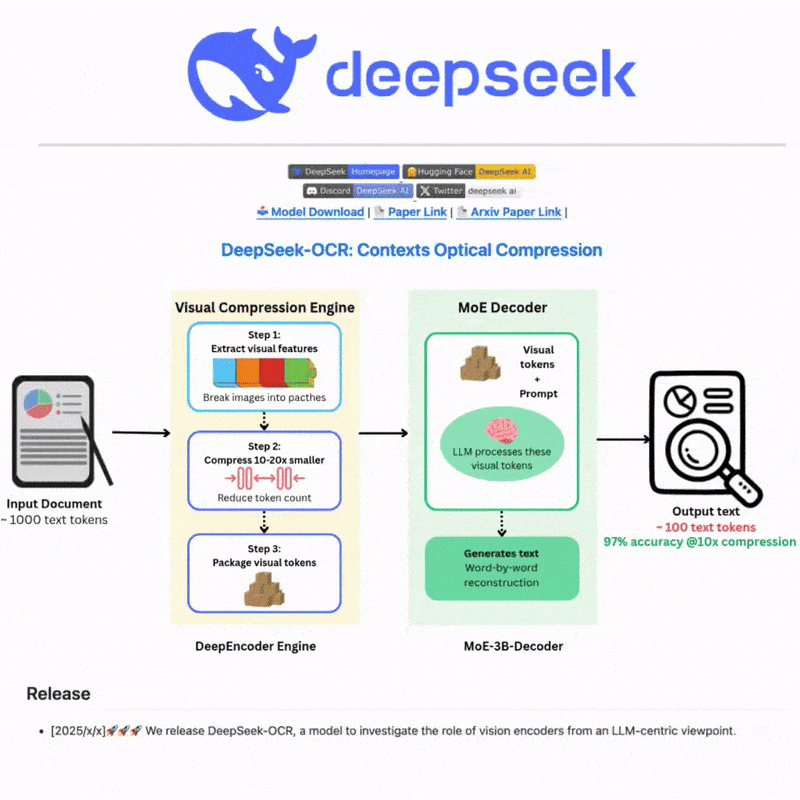
什么是 DeepSeek OCR
DeepSeek OCR 是一个先进的光学字符识别系统,利用尖端的 AI 技术从图像和文档中准确提取文本。采用先进的神经网络和多语言支持构建,为复杂场景提供强大的文本检测和识别能力,提供直观的 Web 界面和强大的 API 集成,实现高效灵活的文本处理工作流。
- 多语言文本识别通过先进的神经网络技术和语言感知处理能力,准确提取超过 80 种语言的图像文本。
- 复杂场景处理使用精密的检测算法处理具有弯曲文本、多方向和复杂背景的挑战性文档布局。
- 高精度识别通过优化的光学字符识别和先进的后处理技术,实现行业领先的文本提取准确度。
DeepSeek OCR 核心功能
专为全球专业人士和开发者设计的先进 AI 驱动文本识别能力。
多语言支持
识别超过 80 种语言的文本,包括中文、英语、阿拉伯语等,具备语言感知字符识别能力。
强大的文本检测
在具有弯曲文本、多方向和挑战性背景条件的复杂布局中检测文本区域。
高速处理
通过优化的推理管道和 GPU 加速快速处理图像,实现实时文本提取结果。
统一框架
利用集成的文本检测和识别系统,提供从图像到文本的端到端提取。
结构化布局恢复
在提取文本时保留文档结构,包括段落、列和表格,并保持适当的格式。
API 集成
通过 RESTful API 和多种编程语言的 SDK 支持,将强大的 OCR 功能集成到您的应用程序中。
人们在 X 上如何评价 DeepSeek-OCR
如果您喜欢使用 DeepSeek OCR,请在 Twitter 上分享您的体验并添加话题标签
Massively unexpected update from DeepSeek: a powerful, high-compression MoE OCR model.
— Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex) October 20, 2025
> In production, DeepSeek-OCR can generate 33 million pages of data per day for LLMs/VLMs using 20 nodes (x8 A100-40G).
They want ALL the tokens. You're welcome to have some too. https://t.co/ks97gjFuhd pic.twitter.com/mXV08ifRle
DeepSeek-OCR has some weird architectural choices for the LLM decoder: DeepSeek3B-MoE-A570M
— elie (@eliebakouch) October 20, 2025
-> uses MHA, no MLA (not even GQA?)
-> 2 shared experts (like DeepSeek V2, but V3 only has 1)
-> quite low sparsity, activation ratio is 12.5%. For V3 it’s 3.52%, for V2 it’s 5%
-> not… pic.twitter.com/nOYptOn3OE
Letsss gooo! DeepSeek just released a 3B OCR model on Hugging Face 🔥
— Vaibhav (VB) Srivastav (@reach_vb) October 20, 2025
Optimised to be token efficient AND scale ~200K+ pages/day on A100-40G
Same arch as DeepSeek VL2
Use it with Transformers, vLLM and more 🤗https://t.co/n4kHihS3At
NEW DeepSeek OCR model that outperforms dots ocr while prefilling 3x less tokens pic.twitter.com/g9T93PndFb
— Casper Hansen (@casper_hansen_) October 20, 2025
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
— vLLM (@vllm_project) October 20, 2025
🧠 Compresses visual contexts up to 20× while keeping… pic.twitter.com/bx3d7LnfaR
🚨 DeepSeek just did something wild.
— Alex Prompter (@alex_prompter) October 20, 2025
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That… pic.twitter.com/5ChoESanC8
is it just me or is this deepseek paper really…weird? like the flagship results are all about compression ratios and they’re gesturing at implications for LLM memory but… it’s an OCR model? are they suggesting that LLMs should ingest OCR embeddings of screenshots of old notes?? pic.twitter.com/ptxkgANIeW
— will brown (@willccbb) October 20, 2025
DeepSeek-OCR: https://t.co/Hww4tubUiS
— Ray Fernando (@RayFernando1337) October 20, 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
— Andrej Karpathy (@karpathy) October 20, 2025
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language… https://t.co/AxRXBdoO0F
Compress everything visually!
— 机器之心 JIQIZHIXIN (@jiqizhixin) October 20, 2025
DeepSeek has just released DeepSeek-OCR, a state-of-the-art OCR model with 3B parameters.
Core idea: explore long-context compression via 2D optical mapping.
Architecture:
- DeepEncoder → compresses high-res inputs into few vision tokens;
-… pic.twitter.com/qbRTi8ViLY